mirror of
https://github.com/LukeHagar/sagivo-blog.git
synced 2025-12-06 04:21:15 +00:00
first commit
This commit is contained in:
5
.gitignore
vendored
Normal file
5
.gitignore
vendored
Normal file
@@ -0,0 +1,5 @@
|
||||
_site
|
||||
.sass-cache
|
||||
.jekyll-cache
|
||||
.jekyll-metadata
|
||||
vendor
|
||||
25
404.html
Normal file
25
404.html
Normal file
@@ -0,0 +1,25 @@
|
||||
---
|
||||
permalink: /404.html
|
||||
layout: default
|
||||
---
|
||||
|
||||
<style type="text/css" media="screen">
|
||||
.container {
|
||||
margin: 10px auto;
|
||||
max-width: 600px;
|
||||
text-align: center;
|
||||
}
|
||||
h1 {
|
||||
margin: 30px 0;
|
||||
font-size: 4em;
|
||||
line-height: 1;
|
||||
letter-spacing: -1px;
|
||||
}
|
||||
</style>
|
||||
|
||||
<div class="container">
|
||||
<h1>404</h1>
|
||||
|
||||
<p><strong>Page not found :(</strong></p>
|
||||
<p>The requested page could not be found.</p>
|
||||
</div>
|
||||
30
Gemfile
Normal file
30
Gemfile
Normal file
@@ -0,0 +1,30 @@
|
||||
source "https://rubygems.org"
|
||||
# Hello! This is where you manage which Jekyll version is used to run.
|
||||
# When you want to use a different version, change it below, save the
|
||||
# file and run `bundle install`. Run Jekyll with `bundle exec`, like so:
|
||||
#
|
||||
# bundle exec jekyll serve
|
||||
#
|
||||
# This will help ensure the proper Jekyll version is running.
|
||||
# Happy Jekylling!
|
||||
gem "jekyll" #, "~> 4.0.0"
|
||||
# This is the default theme for new Jekyll sites. You may change this to anything you like.
|
||||
gem "minima", "~> 2.5"
|
||||
# If you want to use GitHub Pages, remove the "gem "jekyll"" above and
|
||||
# uncomment the line below. To upgrade, run `bundle update github-pages`.
|
||||
gem "github-pages", "~> 203", group: :jekyll_plugins
|
||||
# If you have any plugins, put them here!
|
||||
group :jekyll_plugins do
|
||||
gem "jekyll-feed", "~> 0.12"
|
||||
end
|
||||
|
||||
# Windows and JRuby does not include zoneinfo files, so bundle the tzinfo-data gem
|
||||
# and associated library.
|
||||
install_if -> { RUBY_PLATFORM =~ %r!mingw|mswin|java! } do
|
||||
gem "tzinfo", "~> 1.2"
|
||||
gem "tzinfo-data"
|
||||
end
|
||||
|
||||
# Performance-booster for watching directories on Windows
|
||||
gem "wdm", "~> 0.1.1", :install_if => Gem.win_platform?
|
||||
gem 'jekyll-analytics'
|
||||
259
Gemfile.lock
Normal file
259
Gemfile.lock
Normal file
@@ -0,0 +1,259 @@
|
||||
GEM
|
||||
remote: https://rubygems.org/
|
||||
specs:
|
||||
activesupport (6.0.2.1)
|
||||
concurrent-ruby (~> 1.0, >= 1.0.2)
|
||||
i18n (>= 0.7, < 2)
|
||||
minitest (~> 5.1)
|
||||
tzinfo (~> 1.1)
|
||||
zeitwerk (~> 2.2)
|
||||
addressable (2.7.0)
|
||||
public_suffix (>= 2.0.2, < 5.0)
|
||||
coffee-script (2.4.1)
|
||||
coffee-script-source
|
||||
execjs
|
||||
coffee-script-source (1.11.1)
|
||||
colorator (1.1.0)
|
||||
commonmarker (0.17.13)
|
||||
ruby-enum (~> 0.5)
|
||||
concurrent-ruby (1.1.5)
|
||||
dnsruby (1.61.3)
|
||||
addressable (~> 2.5)
|
||||
em-websocket (0.5.1)
|
||||
eventmachine (>= 0.12.9)
|
||||
http_parser.rb (~> 0.6.0)
|
||||
ethon (0.12.0)
|
||||
ffi (>= 1.3.0)
|
||||
eventmachine (1.2.7)
|
||||
execjs (2.7.0)
|
||||
faraday (1.0.0)
|
||||
multipart-post (>= 1.2, < 3)
|
||||
ffi (1.12.1)
|
||||
forwardable-extended (2.6.0)
|
||||
gemoji (3.0.1)
|
||||
github-pages (203)
|
||||
github-pages-health-check (= 1.16.1)
|
||||
jekyll (= 3.8.5)
|
||||
jekyll-avatar (= 0.7.0)
|
||||
jekyll-coffeescript (= 1.1.1)
|
||||
jekyll-commonmark-ghpages (= 0.1.6)
|
||||
jekyll-default-layout (= 0.1.4)
|
||||
jekyll-feed (= 0.13.0)
|
||||
jekyll-gist (= 1.5.0)
|
||||
jekyll-github-metadata (= 2.12.1)
|
||||
jekyll-mentions (= 1.5.1)
|
||||
jekyll-optional-front-matter (= 0.3.2)
|
||||
jekyll-paginate (= 1.1.0)
|
||||
jekyll-readme-index (= 0.3.0)
|
||||
jekyll-redirect-from (= 0.15.0)
|
||||
jekyll-relative-links (= 0.6.1)
|
||||
jekyll-remote-theme (= 0.4.1)
|
||||
jekyll-sass-converter (= 1.5.2)
|
||||
jekyll-seo-tag (= 2.6.1)
|
||||
jekyll-sitemap (= 1.4.0)
|
||||
jekyll-swiss (= 1.0.0)
|
||||
jekyll-theme-architect (= 0.1.1)
|
||||
jekyll-theme-cayman (= 0.1.1)
|
||||
jekyll-theme-dinky (= 0.1.1)
|
||||
jekyll-theme-hacker (= 0.1.1)
|
||||
jekyll-theme-leap-day (= 0.1.1)
|
||||
jekyll-theme-merlot (= 0.1.1)
|
||||
jekyll-theme-midnight (= 0.1.1)
|
||||
jekyll-theme-minimal (= 0.1.1)
|
||||
jekyll-theme-modernist (= 0.1.1)
|
||||
jekyll-theme-primer (= 0.5.4)
|
||||
jekyll-theme-slate (= 0.1.1)
|
||||
jekyll-theme-tactile (= 0.1.1)
|
||||
jekyll-theme-time-machine (= 0.1.1)
|
||||
jekyll-titles-from-headings (= 0.5.3)
|
||||
jemoji (= 0.11.1)
|
||||
kramdown (= 1.17.0)
|
||||
liquid (= 4.0.3)
|
||||
mercenary (~> 0.3)
|
||||
minima (= 2.5.1)
|
||||
nokogiri (>= 1.10.4, < 2.0)
|
||||
rouge (= 3.13.0)
|
||||
terminal-table (~> 1.4)
|
||||
github-pages-health-check (1.16.1)
|
||||
addressable (~> 2.3)
|
||||
dnsruby (~> 1.60)
|
||||
octokit (~> 4.0)
|
||||
public_suffix (~> 3.0)
|
||||
typhoeus (~> 1.3)
|
||||
html-pipeline (2.12.3)
|
||||
activesupport (>= 2)
|
||||
nokogiri (>= 1.4)
|
||||
http_parser.rb (0.6.0)
|
||||
i18n (0.9.5)
|
||||
concurrent-ruby (~> 1.0)
|
||||
jekyll (3.8.5)
|
||||
addressable (~> 2.4)
|
||||
colorator (~> 1.0)
|
||||
em-websocket (~> 0.5)
|
||||
i18n (~> 0.7)
|
||||
jekyll-sass-converter (~> 1.0)
|
||||
jekyll-watch (~> 2.0)
|
||||
kramdown (~> 1.14)
|
||||
liquid (~> 4.0)
|
||||
mercenary (~> 0.3.3)
|
||||
pathutil (~> 0.9)
|
||||
rouge (>= 1.7, < 4)
|
||||
safe_yaml (~> 1.0)
|
||||
jekyll-analytics (0.1.12)
|
||||
jekyll-avatar (0.7.0)
|
||||
jekyll (>= 3.0, < 5.0)
|
||||
jekyll-coffeescript (1.1.1)
|
||||
coffee-script (~> 2.2)
|
||||
coffee-script-source (~> 1.11.1)
|
||||
jekyll-commonmark (1.3.1)
|
||||
commonmarker (~> 0.14)
|
||||
jekyll (>= 3.7, < 5.0)
|
||||
jekyll-commonmark-ghpages (0.1.6)
|
||||
commonmarker (~> 0.17.6)
|
||||
jekyll-commonmark (~> 1.2)
|
||||
rouge (>= 2.0, < 4.0)
|
||||
jekyll-default-layout (0.1.4)
|
||||
jekyll (~> 3.0)
|
||||
jekyll-feed (0.13.0)
|
||||
jekyll (>= 3.7, < 5.0)
|
||||
jekyll-gist (1.5.0)
|
||||
octokit (~> 4.2)
|
||||
jekyll-github-metadata (2.12.1)
|
||||
jekyll (~> 3.4)
|
||||
octokit (~> 4.0, != 4.4.0)
|
||||
jekyll-mentions (1.5.1)
|
||||
html-pipeline (~> 2.3)
|
||||
jekyll (>= 3.7, < 5.0)
|
||||
jekyll-optional-front-matter (0.3.2)
|
||||
jekyll (>= 3.0, < 5.0)
|
||||
jekyll-paginate (1.1.0)
|
||||
jekyll-readme-index (0.3.0)
|
||||
jekyll (>= 3.0, < 5.0)
|
||||
jekyll-redirect-from (0.15.0)
|
||||
jekyll (>= 3.3, < 5.0)
|
||||
jekyll-relative-links (0.6.1)
|
||||
jekyll (>= 3.3, < 5.0)
|
||||
jekyll-remote-theme (0.4.1)
|
||||
addressable (~> 2.0)
|
||||
jekyll (>= 3.5, < 5.0)
|
||||
rubyzip (>= 1.3.0)
|
||||
jekyll-sass-converter (1.5.2)
|
||||
sass (~> 3.4)
|
||||
jekyll-seo-tag (2.6.1)
|
||||
jekyll (>= 3.3, < 5.0)
|
||||
jekyll-sitemap (1.4.0)
|
||||
jekyll (>= 3.7, < 5.0)
|
||||
jekyll-swiss (1.0.0)
|
||||
jekyll-theme-architect (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-cayman (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-dinky (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-hacker (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-leap-day (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-merlot (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-midnight (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-minimal (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-modernist (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-primer (0.5.4)
|
||||
jekyll (> 3.5, < 5.0)
|
||||
jekyll-github-metadata (~> 2.9)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-slate (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-tactile (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-theme-time-machine (0.1.1)
|
||||
jekyll (~> 3.5)
|
||||
jekyll-seo-tag (~> 2.0)
|
||||
jekyll-titles-from-headings (0.5.3)
|
||||
jekyll (>= 3.3, < 5.0)
|
||||
jekyll-watch (2.2.1)
|
||||
listen (~> 3.0)
|
||||
jemoji (0.11.1)
|
||||
gemoji (~> 3.0)
|
||||
html-pipeline (~> 2.2)
|
||||
jekyll (>= 3.0, < 5.0)
|
||||
kramdown (1.17.0)
|
||||
liquid (4.0.3)
|
||||
listen (3.2.1)
|
||||
rb-fsevent (~> 0.10, >= 0.10.3)
|
||||
rb-inotify (~> 0.9, >= 0.9.10)
|
||||
mercenary (0.3.6)
|
||||
mini_portile2 (2.4.0)
|
||||
minima (2.5.1)
|
||||
jekyll (>= 3.5, < 5.0)
|
||||
jekyll-feed (~> 0.9)
|
||||
jekyll-seo-tag (~> 2.1)
|
||||
minitest (5.14.0)
|
||||
multipart-post (2.1.1)
|
||||
nokogiri (1.10.7)
|
||||
mini_portile2 (~> 2.4.0)
|
||||
octokit (4.15.0)
|
||||
faraday (>= 0.9)
|
||||
sawyer (~> 0.8.0, >= 0.5.3)
|
||||
pathutil (0.16.2)
|
||||
forwardable-extended (~> 2.6)
|
||||
public_suffix (3.1.1)
|
||||
rb-fsevent (0.10.3)
|
||||
rb-inotify (0.10.1)
|
||||
ffi (~> 1.0)
|
||||
rouge (3.13.0)
|
||||
ruby-enum (0.7.2)
|
||||
i18n
|
||||
rubyzip (2.0.0)
|
||||
safe_yaml (1.0.5)
|
||||
sass (3.7.4)
|
||||
sass-listen (~> 4.0.0)
|
||||
sass-listen (4.0.0)
|
||||
rb-fsevent (~> 0.9, >= 0.9.4)
|
||||
rb-inotify (~> 0.9, >= 0.9.7)
|
||||
sawyer (0.8.2)
|
||||
addressable (>= 2.3.5)
|
||||
faraday (> 0.8, < 2.0)
|
||||
terminal-table (1.8.0)
|
||||
unicode-display_width (~> 1.1, >= 1.1.1)
|
||||
thread_safe (0.3.6)
|
||||
typhoeus (1.3.1)
|
||||
ethon (>= 0.9.0)
|
||||
tzinfo (1.2.6)
|
||||
thread_safe (~> 0.1)
|
||||
tzinfo-data (1.2019.3)
|
||||
tzinfo (>= 1.0.0)
|
||||
unicode-display_width (1.6.1)
|
||||
wdm (0.1.1)
|
||||
zeitwerk (2.2.2)
|
||||
|
||||
PLATFORMS
|
||||
ruby
|
||||
|
||||
DEPENDENCIES
|
||||
github-pages (~> 203)
|
||||
jekyll
|
||||
jekyll-analytics
|
||||
jekyll-feed (~> 0.12)
|
||||
minima (~> 2.5)
|
||||
tzinfo (~> 1.2)
|
||||
tzinfo-data
|
||||
wdm (~> 0.1.1)
|
||||
|
||||
BUNDLED WITH
|
||||
2.1.4
|
||||
58
_config.yml
Normal file
58
_config.yml
Normal file
@@ -0,0 +1,58 @@
|
||||
# Welcome to Jekyll!
|
||||
#
|
||||
# This config file is meant for settings that affect your whole blog, values
|
||||
# which you are expected to set up once and rarely edit after that. If you find
|
||||
# yourself editing this file very often, consider using Jekyll's data files
|
||||
# feature for the data you need to update frequently.
|
||||
#
|
||||
# For technical reasons, this file is *NOT* reloaded automatically when you use
|
||||
# 'bundle exec jekyll serve'. If you change this file, please restart the server process.
|
||||
#
|
||||
# If you need help with YAML syntax, here are some quick references for you:
|
||||
# https://learn-the-web.algonquindesign.ca/topics/markdown-yaml-cheat-sheet/#yaml
|
||||
# https://learnxinyminutes.com/docs/yaml/
|
||||
#
|
||||
# Site settings
|
||||
# These are used to personalize your new site. If you look in the HTML files,
|
||||
# you will see them accessed via {{ site.title }}, {{ site.email }}, and so on.
|
||||
# You can create any custom variable you would like, and they will be accessible
|
||||
# in the templates via {{ site.myvariable }}.
|
||||
|
||||
title: Sagiv Ofek - Blog
|
||||
email: sagiv@sagivo.com
|
||||
description: Software Engineering Leadership
|
||||
baseurl: "" # the subpath of your site, e.g. /blog
|
||||
url: "https://sagivo.com" # the base hostname & protocol for your site, e.g. http://example.com
|
||||
twitter_username: sagivo
|
||||
github_username: sagivo
|
||||
linkedin_username: sagivo
|
||||
|
||||
# Build settings
|
||||
theme: minima
|
||||
plugins:
|
||||
- jekyll-feed
|
||||
- jekyll-analytics
|
||||
|
||||
# Exclude from processing.
|
||||
# The following items will not be processed, by default.
|
||||
# Any item listed under the `exclude:` key here will be automatically added to
|
||||
# the internal "default list".
|
||||
#
|
||||
# Excluded items can be processed by explicitly listing the directories or
|
||||
# their entries' file path in the `include:` list.
|
||||
#
|
||||
# exclude:
|
||||
# - .sass-cache/
|
||||
# - .jekyll-cache/
|
||||
# - gemfiles/
|
||||
# - Gemfile
|
||||
# - Gemfile.lock
|
||||
# - node_modules/
|
||||
# - vendor/bundle/
|
||||
# - vendor/cache/
|
||||
# - vendor/gems/
|
||||
# - vendor/ruby/
|
||||
|
||||
jekyll_analytics:
|
||||
GoogleAnalytics: # Add, if you want to track with Google Analytics
|
||||
id: UA-54596506-1 # Required - replace with your tracking id
|
||||
BIN
_posts/.DS_Store
vendored
Normal file
BIN
_posts/.DS_Store
vendored
Normal file
Binary file not shown.
132
_posts/2014-09-08-Mastering-Node-js-logs-cc409e8523b3.markdown
Normal file
132
_posts/2014-09-08-Mastering-Node-js-logs-cc409e8523b3.markdown
Normal file
@@ -0,0 +1,132 @@
|
||||
---
|
||||
layout: post
|
||||
title: Mastering Node.js logs
|
||||
description: ''
|
||||
date: '2014-09-08T18:27:19.000Z'
|
||||
categories: []
|
||||
keywords: []
|
||||
slug: /@sagivo/mastering-node-js-logs-cc409e8523b3
|
||||
---
|
||||
|
||||
It’s very easy to debug your node.js application when you’re in development mode, most of the times you just watch on the console output. This is usually good enough to spot some errors and print some states.
|
||||
|
||||
But what happens when you decide to go live? How to access the logs? How to create different log levels?
|
||||
|
||||
```javascript
|
||||
console.log('Free Willy!');
|
||||
```
|
||||
|
||||
#### Manual Logging
|
||||
|
||||
If you want to log only specific things that you want to track, there are easy libraries that let you do so. [Winston](https://github.com/flatiron/winston) is a very popular one. You can log your output to multiple transports at the same time (e.g: file, console…). It’s also supported by 3rd parties cloud services that will be happy to host those outputs for you (more about that next).
|
||||
|
||||
Here is a simple snippet of how to configure winston and log it to both your console and a file:
|
||||
|
||||
```javascript
|
||||
var winston = require('winston');
|
||||
//log your output to a file also
|
||||
winston.add(winston.transports.File, { filename: 'somefile.log' });
|
||||
//log some outputs
|
||||
winston.log('info', 'Hello distributed log files!');
|
||||
winston.error('Who let the dogs out?!');
|
||||
```
|
||||
|
||||
Other common logging tools are [node-bunyan](https://github.com/trentm/node-bunyan), [log4js](https://github.com/nomiddlename/log4js-node) and [loggly](https://github.com/nodejitsu/node-loggly).
|
||||
|
||||
#### Hosting Logs
|
||||
|
||||
You don’t have to login your server and open a file (or even worse — looking at the console) each time you want to see your latest logs.
|
||||
|
||||
There are platy of cloud services that will host your logs so you can access them remotely, aggregate them, query them and even define some alerts for some patterns.
|
||||
|
||||
[Logentries](https://logentries.com/) has a free plan and can easily configure to work with node. To configure, you’ll have to use the [node-logentries](https://github.com/rjrodger/node-logentries) library.
|
||||
|
||||
```javascript
|
||||
var logentries = require('node-logentries');
|
||||
var log = logentries.logger({token:'YOUR_TOKEN'});
|
||||
log.info("I think pandas are ugly");
|
||||
//or connect via winston
|
||||
var winston = require('winston');
|
||||
log.winston(winston);
|
||||
```
|
||||
|
||||
Another logging services is [Loggly](https://www.loggly.com/) — very similar concept and also has a [node sdk](https://github.com/nodejitsu/node-loggly) to directly write logs to this service.
|
||||
|
||||
#### Where Is My Console Output?
|
||||
|
||||
So far we talked about logging some data that you choose, but there are lots of times you just want to watch all the output your console has and even track errors.
|
||||
|
||||
In order to stream your console output we have to understand first how it works.
|
||||
|
||||
#### stdout & stderr
|
||||
|
||||
Standard output (stdout) is the stream where a program writes its output data. The program requests data transfer with the write operation. Unless redirected, standard output is the text terminal which initiated the program.
|
||||
|
||||
Standard error (stderr) is another output stream typically used by programs to output error messages or diagnostics. It is a stream independent of standard output and can be redirected separately. The usual destination is the text terminal which started the program to provide the best chance of being seen even if standard output is redirected (so not readily observed). For example, output of a program in a pipeline is redirected to input of the next program, but errors from each program still go directly to the text terminal.
|
||||
|
||||
When your node app is running, it uses stdout and stderr as it’s output. Each time the software needs to print something (via console.log() or any other commend) it prints it to stdout.
|
||||
|
||||
Each time an error occurred, the system prints it to stderr.
|
||||
|
||||
In production you can’t watch your output (end should not since your node app should run as a daemon process, usually via upstart or forever), this is why it’s better to re-configure stdout and stderr.
|
||||
|
||||
There are several ways to configure it, you can do it within the app by creating another [child-process](http://nodejs.org/api/child_process.html) that handles incoming data. Child-process use spawn which is an EventEmitter object so it’s non-blocking and recommended.
|
||||
|
||||
```js
|
||||
var child = require('child_process');
|
||||
var myREPL = child.spawn('bash');
|
||||
//pipe node process to new child process
|
||||
process.stdin.pipe(myREPL.stdin);
|
||||
myREPL.stdin.on("end", function() { process.exit(0);});
|
||||
//hook to incomming data event
|
||||
myREPL.stdout.on('data', function (data) {
|
||||
console.log('we got new data here!',data);
|
||||
});
|
||||
myREPL.stderr.on('data', function (data) {
|
||||
console.log('oh oh :(' + data);
|
||||
});
|
||||
```
|
||||
|
||||
An easier way to configure the stderr and stdout is by starting the node app. Simply use:
|
||||
|
||||
```js
|
||||
#log both output and error to same file
|
||||
node app.js >> /path/to/app.log 2>&1
|
||||
#use seperate files for errors and outputs
|
||||
node app.js >> /path/to/app.log 2>> /path/to/err.log
|
||||
```
|
||||
|
||||
This will tell the node process to redirect all the output to the files you specify. You can also change the \`>>\` sign to \`>\` if you want to override the previous file each time you start the app.
|
||||
|
||||
Once you pipe all your outputs to files you can use the services i mentioned above to track those files in real time and display them there. Here is more info about how to track file using [Logentries agent](https://logentries.com/doc/agent/)
|
||||
|
||||
and using [Loggly](https://community.loggly.com/customer/portal/articles/1225986-rsyslog-configuration?b_id=50#).
|
||||
|
||||
#### Even More Configurable Logging
|
||||
|
||||
But wait, that’s not all! Now that we know how to pipe our outputs to files/services we can even control the syntax we want in some cases.
|
||||
|
||||
We can connect to specific events and control the output.
|
||||
|
||||
Here are some samples for handling with express.js and mongoose:
|
||||
|
||||
```js
|
||||
var express = require('express');
|
||||
var app = express();
|
||||
//configure express logging
|
||||
var logStream = {
|
||||
write: function(message, encoding) {
|
||||
return console.log("EXPRESS: " + message);
|
||||
}
|
||||
};
|
||||
app.use(express.logger({stream: logStream}));
|
||||
//configure mongoose logging
|
||||
var mongoose = require('mongoose');
|
||||
mongoose.set('debug', function(collectionName, method, query, doc){
|
||||
console.log("DB: ", collectionName, method, JSON.stringify(query));
|
||||
});
|
||||
```
|
||||
|
||||
#### The Bottom line
|
||||
|
||||
Logs are important tool both for development and production. There are manny ways to define where the log output should go and how to see it, use the one suites your needs and follow your logs :)
|
||||
@@ -0,0 +1,56 @@
|
||||
---
|
||||
layout: post
|
||||
title: Bitcoin on Node.js — do it yourself
|
||||
description: ''
|
||||
date: '2014-09-10T04:28:00.000Z'
|
||||
categories: []
|
||||
keywords: []
|
||||
slug: /@sagivo/bitcoin-on-node-js-do-it-yourself
|
||||
---
|
||||
|
||||
([to the project page in github](https://github.com/sagivo/accept-bitcoin "accept bitcoin"))
|
||||
|
||||
Bitcoin is huge, we know it.
|
||||
|
||||
While bitcoin ecosystem is starting to develop, more and more companies are offering solutions for developers to collect bitcoins while getting a cut out of this. The big vision of “you own your money” is disrupt buy services like [coinbase](http://coinbase.com) who hold your money for you.
|
||||
|
||||
I don’t like it.
|
||||
|
||||
I believe a tool to accept money online should be free. This is why I decided to develop a tool like that. Developing a way to accept bitcoins online involve a lot of challenges. Let’s assume you build an online store to sell unicorns made out from bear. Here are some challenges you’ll face:
|
||||
|
||||
* **Who sent me the money?** if you ask your users to pay to your address, how do you know who of them paid? You prefer not to exposed your address at all and save it offline in [cold storage](https://en.bitcoin.it/wiki/Cold_storage).
|
||||
* **How can i be sure i got the money?** How can i know the money is actually there?
|
||||
* **I want a complete control on events **— you want to know when you got your payment, or expire your offer after some time.
|
||||
* **I don’t want to install any bitcoin client **— in order to communicate with the bitcoin network you have to install client on your servers. this client basically sync the entire bitcoin transactions ever made just in order to know that joe have money to pay for your bear unicorn. This client consume a lot of CPU resources, network traffic and storage and could be overkill for simple small size sites.
|
||||
* **I want it to be open-sourced** — bitcoin is free and open, so as the tool used to build it.
|
||||
|
||||
Having all those challenges in mind, i decided to develop [accept-bitcoin](https://github.com/sagivo/accept-bitcoin) library. This tool allow any developer to quickly, safely and efficiently accept bitcoins in their projects. Accept-bitcoin (AC) was built on top of [bitcore](https://github.com/bitpay/bitcore) library and offer answer to the challenges above. The process is simple:
|
||||
|
||||
_A user want to buy your unicorn bear item -> AC generate a random_ **_new_** _bitcoin address just for this sale -> a user get the address and pay -> you get a notification once a payment was made in a minimum security level you decide -> you thank the user for paying -> AC transfers the income to your safe (and secret) address -> user gets his unicorn bear item, you happy_.
|
||||
|
||||
This flow solve the challenges above:
|
||||
|
||||
* AC creates ad-hoc address for each sale. Each customer pays to different generated address — this way you can know who paid for what.
|
||||
* You can specify your own confirmation level — The bitcoin miners will confirm it for you. AC will monitor the current confirmations level and notify you once the minimum level you want has been reached (if at all).
|
||||
* You don’t need to install any bitcoin RPC client! AC will communicate with the bitcoin network for you using tools like [blockr](http://blockr.io/). AC will communicate with the network only to monitor income funds and nothing else.
|
||||
* [It’s all open source! Fork it, star it, contribute to it. Hooray!!](https://github.com/sagivo/accept-bitcoin)
|
||||
|
||||
So how can you use this tool? Here’s a sample to demonstrate how easy it is:
|
||||
|
||||
```js
|
||||
var settings = {network: 'live'};
|
||||
var acceptBitcoin = require('accept-bitcoin');
|
||||
ac = new acceptBitcoin('YOUR_BITCOIN_ADDRESS', settings);
|
||||
//generate new key for transaction
|
||||
key = ac.generateAddress({alertWhenHasBalance: true});
|
||||
console.log("Hello buyer! please pay to: " + key.address());
|
||||
key.on('hasBalance', function(amount){
|
||||
console.log("thanks for paying me " + amount); //do stuff
|
||||
//transfer the amount recived to your account
|
||||
key.transferBalanceToMyAccount(function(err, d){
|
||||
if (d.status === 'success') console.log("Cool, the bitcoins are in my private account!");
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
You can find more instructions and info on the [accept-bitcoin project site](https://github.com/sagivo/accept-bitcoin).
|
||||
87
_posts/2014-11-08-Permutations---Ruby-Style-Recursion.md
Normal file
87
_posts/2014-11-08-Permutations---Ruby-Style-Recursion.md
Normal file
@@ -0,0 +1,87 @@
|
||||
---
|
||||
layout: post
|
||||
title: 'Permutations — Ruby Style Recursion '
|
||||
description: ''
|
||||
date: '2014-11-08T22:53:00.000Z'
|
||||
categories: []
|
||||
keywords: []
|
||||
slug: /@sagivo/permutations-ruby-style-recursion-e08120f2b997
|
||||
---
|
||||
|
||||
The permutation problem is as follows: Given a list of items, list all the possible orderings of those items.
|
||||
|
||||
We typically list permutations of letters. For example, here are all the permutations of CAT:
|
||||
|
||||
CAT
|
||||
|
||||
CTA
|
||||
|
||||
ACT
|
||||
|
||||
ATC
|
||||
|
||||
TAC
|
||||
|
||||
TCA
|
||||
|
||||
There are several different permutation algorithms, but since recursion an emphasis of the course, a recursive algorithm to solve this problem will be presented. (Feel free to come up with an iterative algorithm on your own.)
|
||||
|
||||
**The idea is as follows:**
|
||||
|
||||
In order to list all the permutations of CAT, we can split our work into three groups of permutations:
|
||||
|
||||
1) Permutations that start with C.
|
||||
|
||||
2) Permutations that start with A.
|
||||
|
||||
3) Permutations that start with T.
|
||||
|
||||
The other nice thing to note is that when we list all permutations that start with C, they are nothing put strings that are formed by attaching C to the front of ALL permutations of “AT”. This is nothing but another permutation problem!!!
|
||||
|
||||
**Number of recursive calls**
|
||||
|
||||
Often times, when recursion is taught, a rule of thumb given is, “recursive functions don’t have loops.” Unfortunately, this rule of thumb is exactly that; it’s not always true. An exception to it is the permutation algorithm.
|
||||
|
||||
The problem is that the number of recursive calls is variable. In the example on the previous page, 3 recursive calls were needed. But what if we were permuting the letters in the word, “COMPUTER”? Then 8 recursive calls (1 for each possible starting letter) would be needed.
|
||||
|
||||
In essence, we see the need for a loop in the algorithm:
|
||||
|
||||
```
|
||||
for (each possible starting letter)
|
||||
list all permutations that start with that letter
|
||||
```
|
||||
|
||||
**What is the terminating condition?**
|
||||
|
||||
Permuting either 0 or 1 element. In the code that will be presented in this lecture, the terminating condition will be when 0 elements are being permuted. (This can be done in exactly one way.)
|
||||
|
||||
**Use of an extra parameter**
|
||||
|
||||
As we have seen, recursive functions often take in an extra parameter as compared to their iterative counterparts. For the pemutation algorithm, this is also the case. In the recursive characterization of the problem, we have to specify one more piece of information in order for the chain of recursive calls to work. Here is what our function prototype, pre-conditions and post-conditions will look like:
|
||||
|
||||
```
|
||||
// Pre-condition: str is a valid C String, and k is non-negative
|
||||
// and less than or equal to the length of str.
|
||||
// Post-condition: All of the permutations of str with the first k
|
||||
// characters fixed in their original positions
|
||||
// are printed. Namely, if n is the length of str,
|
||||
// then (n-k)! permutations are printed.
|
||||
void RecursivePermute(char str\[\], int k);
|
||||
```
|
||||
|
||||
Utilizing this characterization, the terminating condition is when k is equal to the length of the string str, since this means that all the letters in str are fixed. If this is the case, we just want to print out that one permutation.
|
||||
|
||||
Otherwise, we want a for loop that tries each character in index k. It’ll look like this:
|
||||
|
||||
```js
|
||||
for (j=k; j<strlen(str); j++) {
|
||||
ExchangeCharacters(str, k, j);
|
||||
RecursivePermute(str, k+1);
|
||||
ExchangeCharacters(str, j, k);
|
||||
}
|
||||
```
|
||||
where ExchangeCharacters swaps the two characters in str with the given indexes passed in as the last two parameters.
|
||||
|
||||
|
||||
Here is the code is ruby:
|
||||
[https://gist.github.com/sagivo/b7d772d9b3b531f9996f](https://gist.github.com/sagivo/b7d772d9b3b531f9996f)
|
||||
208
_posts/2015-09-30-Go-Native---Calling-C---From-NodeJS.md
Normal file
208
_posts/2015-09-30-Go-Native---Calling-C---From-NodeJS.md
Normal file
@@ -0,0 +1,208 @@
|
||||
---
|
||||
layout: post
|
||||
title: Go Native — Calling C++ From NodeJS
|
||||
description: ''
|
||||
date: '2015-09-30T12:24:56.000Z'
|
||||
categories: []
|
||||
keywords: []
|
||||
slug: /@sagivo/go-native-calling-c-from-nodejs-614a2cbfebc1
|
||||
---
|
||||
|
||||
(full repo can be found [here](https://github.com/sagivo/nodejs-addons))
|
||||
|
||||
### Node.js Addons
|
||||
|
||||
Sometimes you want to use your existing c++ code directly from your node app.
|
||||
|
||||
You can do it using Node.js addons, [nan](https://github.com/nodejs/nan) and [node-gym](https://github.com/nodejs/node-gyp) library.
|
||||
|
||||
```c++
|
||||
#include <node.h>
|
||||
|
||||
namespace demo {
|
||||
using v8::FunctionCallbackInfo;
|
||||
using v8::Isolate;
|
||||
using v8::Local;
|
||||
using v8::Object;
|
||||
using v8::String;
|
||||
using v8::Value;
|
||||
|
||||
void Method(const FunctionCallbackInfo<Value>& args) {
|
||||
Isolate* isolate = args.GetIsolate();
|
||||
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "world"));
|
||||
}
|
||||
|
||||
void init(Local<Object> exports) {
|
||||
NODE_SET_METHOD(exports, "hello", Method);
|
||||
}
|
||||
|
||||
NODE_MODULE(addon, init)
|
||||
}
|
||||
```
|
||||
|
||||
This will create a simple c++ program. The first thing you can notice is that we are importing bunch of v8 libreries. As you know, v8 is the engine that powers node behind the scenes and we will talk more about better approaches to this later.
|
||||
NODE\_MODULE(addon, init) is your entry point. The addon will be under the addon namespace and will first call the init function.
|
||||
|
||||
```c++
|
||||
void init(Local<Object> exports) {
|
||||
NODE_SET_METHOD(exports, "hello", Method);
|
||||
}
|
||||
```
|
||||
|
||||
here we are getting a Local object as param and declaring a new method called hello.
|
||||
|
||||
A [Local](http://izs.me/v8-docs/classv8_1_1Local.html) type is managed by the v8 Engine.
|
||||
|
||||
Next, we bind the hello command to the Method method:
|
||||
|
||||
```c++
|
||||
void Method(const FunctionCallbackInfo<Value>& args) {
|
||||
Isolate* isolate = args.GetIsolate();
|
||||
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "world"));
|
||||
}
|
||||
```
|
||||
|
||||
This method will be called when the node will call hello. Here we are getting the current Isolate data and setting the return value to be world.
|
||||
|
||||
#### binding.gyp
|
||||
|
||||
Next, let’s create a binding.gyp file with instructions to be used by the node-gyp library:
|
||||
|
||||
```json
|
||||
{
|
||||
"targets": [
|
||||
{
|
||||
"target_name": "addon",
|
||||
"sources": [ "hello.cc" ]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Here we can set the name and source of the addon we have.
|
||||
|
||||
There are many other params [you can configure in this file](https://github.com/nodejs/node-gyp#the-bindinggyp-file).
|
||||
|
||||
#### Makefile
|
||||
|
||||
Create a Makefile file that specify the build instructions:
|
||||
|
||||
```
|
||||
all: build
|
||||
build: build_node
|
||||
build_node: node-gyp rebuild
|
||||
```
|
||||
|
||||
#### JS code
|
||||
|
||||
Now, all we have left is to do is to compile the code and import it to node.
|
||||
|
||||
We can just use npm install to do it. This will call node-gyp rebuild on our native code (we can also call it ourself manually) and output the result as a binary compiled node file to build/Release/addon.node.
|
||||
|
||||
The next step is to import it from our node app:
|
||||
|
||||
```js
|
||||
var addon = require('./build/Release/addon');
|
||||
console.log(addon.hello()); // will print 'world'
|
||||
```
|
||||
|
||||
And that’s it! We just made our first native call from node.
|
||||
|
||||
### Advanced use
|
||||
|
||||
Node is moving fast, also the underline v8 engine. This is why it is best to get some use of the [nan](https://github.com/nodejs/nan) npm library. The idea behind is to support a unify wrapper on top of the v8 engine so your native calls will be v8 version agnostic.
|
||||
|
||||
Most of the calls will have similar signiture and this way we won’t need to change the compiled version any time there’s a new one.
|
||||
|
||||
Let’s look on a slightly more advanced sample- the first change we will need is to add this code to the binding.gyp file under targets:
|
||||
|
||||
```c++
|
||||
"include_dirs" : ["<!(node -e \"require('nan')\")"]
|
||||
```
|
||||
|
||||
After installing nan, we need to import it by adding this line at the head of hello.cc:
|
||||
|
||||
```c++
|
||||
#include <nan.h>
|
||||
```
|
||||
|
||||
Now, let’s change our Method function a bit:
|
||||
|
||||
```c++
|
||||
void Method(const FunctionCallbackInfo<Value>& args) {
|
||||
v8::String::Utf8Value nameFromArgs(args[0]->ToString());
|
||||
std::string name = std::string(*nameFromArgs);
|
||||
std::string response = "hello " + name;
|
||||
|
||||
args.GetReturnValue().Set(Nan::New(response).ToLocalChecked());
|
||||
}
|
||||
```
|
||||
|
||||
This time we will send a param from node.js to the c++ code. The way we do it is using the args in the functions’ signature.
|
||||
|
||||
Notice that this time we’re using [Nan::New](https://github.com/nodejs/nan/blob/master/doc/new.md#nannew) that returns v8::Local object.
|
||||
|
||||
From the node side, let’s call it with a parameter this time:
|
||||
|
||||
```js
|
||||
var addon = require('./build/Release/addon');
|
||||
console.log(addon.hello('Sam')); // will print "Hello Sam"
|
||||
```
|
||||
|
||||
### Memory leaks
|
||||
|
||||
Yes, once we write in c++ we can forget about gc and need to do everything ourselves. Nan (or v8) can handle it for us in case we declare new object of type Local but in case we allocate new objects we have to remember to free the memory.
|
||||
|
||||
#### Buffers
|
||||
|
||||
A good example of bug that may happen is the use of buffer. Let’s assume you have a function that generate a buffer and returns it to node:
|
||||
|
||||
```c++
|
||||
void GetBuffer(const FunctionCallbackInfo<Value>& args) {
|
||||
char *data;
|
||||
size_t length;
|
||||
GetSomeBufferData(data, length);
|
||||
MaybeLocal<Object> buffer = Nan::NewBuffer(data, length);
|
||||
args.GetReturnValue().Set(buffer.ToLocalChecked());
|
||||
}
|
||||
```
|
||||
|
||||
This code can create a memory leak as explained [here](https://github.com/nodejs/nan/blob/master/doc/buffers.md#api_nan_new_buffer):
|
||||
|
||||
> Note that when creating a Buffer using Nan::NewBuffer() and an existing char\*, it is assumed that the ownership of the pointer is being transferred to the new Buffer for management. When a node::Buffer instance is garbage collected and a FreeCallback has not been specified, data will be disposed of via a call to free(). You must not free the memory space manually once you have created a Buffer in this way.
|
||||
|
||||
Using Nan::NewBuffer will not free the char\* from memory so you will have to do it yourself. The problem is that by adding delete \[\]data you’re getting into a race condition — the data can be deleted from the buffer before returning to node.
|
||||
|
||||
The solution in this case will be to use [Nan::CopyBuffer](https://github.com/nodejs/nan/blob/master/doc/buffers.md#nancopybuffer) instead:
|
||||
|
||||
```c++
|
||||
void GetBuffer(const FunctionCallbackInfo<Value>& args) {
|
||||
char *data;
|
||||
size_t length;
|
||||
GetSomeBufferData(data, length);
|
||||
MaybeLocal<Object> buffer = Nan::CopyBuffer(data, length);
|
||||
delete []data;
|
||||
args.GetReturnValue().Set(buffer.ToLocalChecked());
|
||||
}
|
||||
```
|
||||
|
||||
It might be a bit slower since we call memcpy() to create a new instance of the buffer but this way you can remove your char\* and avoid memory leaks or race conditions.
|
||||
|
||||
#### Upgrading to Node 4.x
|
||||
|
||||
We at [Brewster](https://www.brewster.com) needed to upgrade an old codebase to a newer node version.
|
||||
|
||||
This upgrade was not as trivial as we wanted since the new 4.x node uses the new v8 engine that introduced a lot of [api changes](https://docs.google.com/document/d/1g8JFi8T_oAE_7uAri7Njtig7fKaPDfotU6huOa1alds/edit):
|
||||
|
||||
* Introduction of MaybeLocal<> and Maybe<> APIs
|
||||
* Force explicit Isolate\* parameter on all external APIs
|
||||
* Deprecate unused Map/Set FromArray factory methods
|
||||
* Deprecate v8::Handle
|
||||
* NanNew -> Nan::New
|
||||
|
||||
And [much more changes](https://nodesource.com/blog/cpp-addons-for-nodejs-v4). Also, we needed to upgrade our gcc compiler to version 4.8 and up in order to compile the new v8.
|
||||
I suggest reading through the v8 and nan docs in order to see what are the main point you need to address once upgrading.
|
||||
|
||||
That’s it, this is the basic of working with c++ and node together using addons.
|
||||
|
||||
Once again, The code sample can be found at my [GitHub repo](https://github.com/sagivo/nodejs-addons).
|
||||
38
_posts/2015-11-05-Hackathon-As-Part-Of-Your-Company-DNA.md
Normal file
38
_posts/2015-11-05-Hackathon-As-Part-Of-Your-Company-DNA.md
Normal file
@@ -0,0 +1,38 @@
|
||||
---
|
||||
layout: post
|
||||
title: Hackathon As Part Of Your Company DNA
|
||||
description: ''
|
||||
date: '2015-11-05T11:47:30.000Z'
|
||||
categories: []
|
||||
keywords: []
|
||||
slug: /@sagivo/hackathon-as-part-of-your-company-dna-45b9a0c0472f
|
||||
---
|
||||
|
||||
Yahoo, google, Facebook, BBC, NASA, AT&T have one thing in common — they all have hackathon regularly. A hackathon is not only for weekends and can be incorporated as part of your company’s DNA.
|
||||
|
||||
#### What is a hackathon?
|
||||
|
||||
> (also known as a hack day, hackfest or codefest) a hackathon is an event, in which computer programmers and others involved in software development and hardware development (graphic designers, interface designers and project managers) collaborate intensively on software projects in competition with other teams.\[1\] Occasionally, there is a hardware component as well. Hackathons typically last between a day to a week. in many cases the goal is to create usable software. Hackathons tend to have a specific focus, which can include the programming language used, the operating system, an application, an API, or the subject and the demographic group of the programmers. In other cases, there is no restriction on the type of software being created.
|
||||
> ([wikipedia](https://en.wikipedia.org/wiki/Hackathon))
|
||||
|
||||
Even though hackathon are tend to concentrate around tech events, it does not have to only be tech related. Hackathon is an event where you group people together around one task/competition and give them the freedom to innovate and find solutions for that.
|
||||
|
||||
When we [started working](http://techcrunch.com/2015/10/23/brewster-contacts-app-team-gets-acqui-hired-by-burger-king-owner-rbi-brewster-lives-on/) at [RBI](http://rbi.com), we decided to dedicate our first week to a hackathon. We thought it would be a good idea to start by “thinking outside-of-the-box”, create a fun working environment and encourage learning and innovation.
|
||||
|
||||
#### Do it right
|
||||
|
||||
in order to have a successful hackathon there are few key items you must have:
|
||||
|
||||
* Goal — The goal should be simple to understand and interesting enough to achieve. “We should build x or we should have y”.
|
||||
Timeline — You should know when the hack starts, when it ends and if you have any major checkpoints along the way. A 3-days hack is usually the most common hack length since it can fit into a weekend or not take too much resource from the company if it’s during the week. Less than that could be too short to develop anything noticeable and more than a week could be too much effort.
|
||||
Judging Criteria — It’s very motivating to choose winners. You can choose more than one and have different categories. However, people should know what the criteria(s) is, that way they can aim towards a specific goal.
|
||||
* Voting — Usually a selected group of people that specialize in each category can select the winners. If you do it at work, I suggest to let the employees vote for one another. Perhaps let them choose a discrete vote so that office-politics will not affect the decisions.
|
||||
Be Creative — People normally tend to stick to solving problem in the most familiar way. The whole idea behind a hackathon is to get outside of yourself and approach a problem from a different angle. For example, at our hack week we had one rule — you cannot work with technology you already know. This way even if you didn’t win, at least you learned something new. Sometimes “forcing” to learn will cause you to think in a new way that you’re not use to.
|
||||
* Prizes — Fact, people will work harder than usual to win. The prize should be related to the contest and the contesters. more important than the actual prize is the value of winning. It’s not unusual to see people stay up late (sometimes even sleep in) during the hackathon. They do exhaust themselves because they want to win. Its not the prize that drives them, its the recognition. That alone is a main motivation for them to work hard and come out with a game changing innovation.
|
||||
* Collaborate — Having a competition does not mean isolation. It’s a good idea to encourage collaboration between the teammates. Helping each other can help the general group culture later on when they face “Real World” problems. Make the hackathon a learning experience. Hackers want to flex their creative muscles and learn new skills. You want the developers, designers and product people to come out of the hackathon feeling as though they’ve learned something together.
|
||||
|
||||
#### Hack your culture
|
||||
|
||||
From the taxi app EasyTaxi to Facebook’s like button — a lot of products started as crazy hackathon ideas. However, some of them diverge into a actual product and gain massive traction.
|
||||
Hackathons give people the freedom to explore new paths, something that not possible during their daily routine. Sometimes this new path can lead to great discovery that can affect the entire company.
|
||||
By maintaining a hackathon culture in your workplace you’ll keep your employees happy, encourage innovation, eagerness to learn new things. Who know, you may find your next great product.
|
||||
111
_posts/2018-01-19-The-missing-Dictionary-in-Solidity.md
Normal file
111
_posts/2018-01-19-The-missing-Dictionary-in-Solidity.md
Normal file
@@ -0,0 +1,111 @@
|
||||
---
|
||||
layout: post
|
||||
title: The missing Dictionary in Solidity
|
||||
description: (link to the github repo)
|
||||
date: '2018-01-19T15:49:55.276Z'
|
||||
categories: []
|
||||
keywords: []
|
||||
slug: /@sagivo/the-missing-dictionary-in-solidity-67b15e0c6d94
|
||||
---
|
||||
|
||||
([link to the github repo](https://github.com/sagivo/solidity-utils))
|
||||
|
||||
If you ever wanted to interact with smart contracts and build on top of the block-chain before you probably heard of Solidity. That’s the programing language behind the Ethereum smart contracts. Being a new language comes with missing some typical data-structures you got used to in other languages. In this post I’ll describe the journey of creating the an `dictionary` data structure in Solidity.
|
||||
|
||||
### Define: <Dictionary>
|
||||
|
||||
Coming from languages like javascript, ruby, java, c# and others, `Dictionary` might represent different things usually known as `hash`/`map`/`hashmap`/`hashtable` etc… In this post I’ll define `Dictionary` as a generic data structure that allows you to do these basic operations:
|
||||
|
||||
`Set(key, value)` — store arbitrary value for a given key.
|
||||
|
||||
`Get(key) -> value` — retrieve a value for a specific key.
|
||||
|
||||
`Remove(key)`— remove a key.
|
||||
|
||||
`Keys() -> [id1, id2, ...id-n]` — get a list of all keys. (**The missing piece in Solidity**).
|
||||
|
||||
### The Current Problem
|
||||
|
||||
The easy part would be `Set` and `Get` as we can simply use the existed `[mapping](http://solidity.readthedocs.io/en/develop/types.html#mappings)` data type for it. Think of `mapping` as a hash table connecting a hashed key to a value. [Hash tables](https://en.wikipedia.org/wiki/Hash_table) will allow us to easily achieve O(1) efficiency for both `Get` and `Set`. The issue begins when we want to iterate over all the keys/values in the hash table.
|
||||
|
||||
In most of the modern languages we have a built-in `.keys()` function allows us to easily retrieve all the keys of a map. In solidity we don’t have it:
|
||||
|
||||
> Mappings are not iterable, but it is possible to implement a data structure on top of them. For an example, see [iterable mapping](https://github.com/ethereum/dapp-bin/blob/master/library/iterable_mapping.sol). \[[source](http://solidity.readthedocs.io/en/develop/types.html#mappings)\]
|
||||
|
||||
Ethereum offers a library that implement [iterable mapping](https://github.com/ethereum/dapp-bin/blob/master/library/iterable_mapping.sol). This solution combine an `array` together with `mapping` so each time you add an item to the hash table you also add another item to the extra array. This structure has some few problems:
|
||||
|
||||
**Data duplication** — the Ids stored in both mapping and array. As you know, storing information on the blockchain is expensive so you want to minimize the footprint as much as possible.
|
||||
|
||||
**Inefficient store **— when you delete an item from the map, the array simply set it’s index to 0. assuming you stored 1M items and deleted them all, you’ll have an array with 1M indexes assigned to initial value.
|
||||
|
||||
**Inefficient iteration & removal **— since the array that tracks ids is in sequential order, getting the next item means looping through items that might be deleted so if for instance the indexes in the array between `n` to `n+x` deleted means you’ll have `x` unneeded iteration operations that you wasted gas on just to get your next id.
|
||||
|
||||
### Can we do better?
|
||||
|
||||
The question I love to ask in each job interview is relevant here more than ever — can we do better? Smart contract requires gas to work. Since gas priced by code efficiency and storage requirements, we have to come up with better, leaner, faster data structure.
|
||||
|
||||
The main problem on the solution above is choosing array as a data structure to store and track ids of the mapping. Can we find a more efficient way to keep all the data in one place (to avoid duplication) yet enforce connection between ids so we can iterate and output all keys?
|
||||
|
||||
**First attempt**
|
||||
|
||||
One data structure that might be a good start is a [linked list](https://en.wikipedia.org/wiki/Linked_list). Linked list allows you easily track the next node so iteration will be very easy with no “gaps” between. Each node simply points on the next node.
|
||||
|
||||
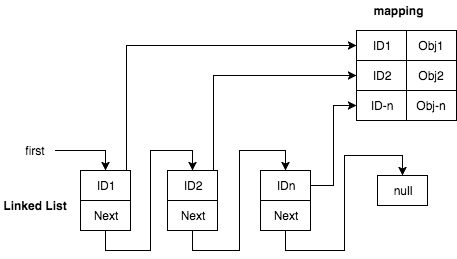
|
||||
linked-list nodes combined with hash-table. each list node represent hash key
|
||||
|
||||
Pros —no mode “gaps” or array copy in case of removing a node. as we’re not using an array we can easily delete an item just by changing the `next` pointers.
|
||||
|
||||
Cons
|
||||
|
||||
1. Efficiency — to get the next item of a given key, or to delete a node we will need to iterate over the linked-list items yielding O(N) for `remove` operation.
|
||||
2. Data duplication — keys exists both in the hash table and linked list.
|
||||
|
||||
**Final solution**
|
||||
|
||||
To avoid data duplication of keys and to get better retrieval time what if we can combine linked-list with hash map as one data-structure? This new data structure will be represented as a hash-map where each value is a linked-list node pointing on the next node and also containing the data.
|
||||
|
||||
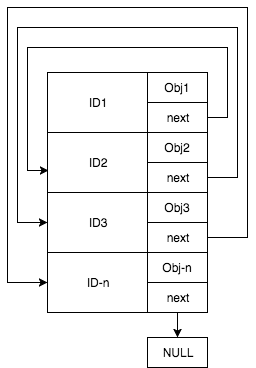
|
||||
hash-table where each value is a linked-list node pointing on the next key
|
||||
|
||||
This data structure will combine the good of both linked-list and hash-table together.
|
||||
|
||||
Inserting or removing an item will require us to simply add/delete a key in the hash-table and adjust the node pointers — achieving O(1) performance (simple hash-map lookup).
|
||||
|
||||
Storing the nodes as part of the hash-map will also prevent a data-duplication among two different data structures as keys are saved only in one place (as keys of the mapping table) achieving less storage.
|
||||
|
||||
### Future improvements
|
||||
|
||||
1. Using [double linked list](https://en.wikipedia.org/wiki/Doubly_linked_list) to iterate over the array both ways.
|
||||
2. Storing a `size` variable to easily get the number of items.
|
||||
3. Using hash table as a data-structure to host the double-linked-list nodes will allow us to add more operations like `insertBefore`, `insertAfter`, `insertBeginning` and `insertEnd`.
|
||||
4. Guarantee keys order based on inserting strategy (append beginning/end).
|
||||
5. Extend the base node struct to allow different types as keys (like strings) and values.
|
||||
|
||||
### Use it in your smart contract today
|
||||
|
||||
I created a [repo of solidity utils](https://github.com/sagivo/solidity-utils) (includes all the suggested improvements) so everyone can easily use it in their projects. To import the new dictionary data structure all you need to do is:
|
||||
|
||||
```js
|
||||
pragma solidity ^0.4.0;
|
||||
// import the contract
|
||||
import "github.com/sagivo/solidity-utils/contracts/lib/Dictionary.sol";
|
||||
// have fun
|
||||
contract Foo {
|
||||
// declare and use new Dictionary structure
|
||||
using Dictionary for Dictionary.Data;
|
||||
Dictionary.Data private dic;
|
||||
|
||||
function Foo() public view returns (uint) {
|
||||
dic.set(1, "value");
|
||||
dic.set(2, "foo");
|
||||
dic.set(123, "bar");
|
||||
dic.set(1, "new value");
|
||||
// get an item
|
||||
dic.get(2); // => '0x666f6f' (byte hex of 'foo')
|
||||
// get all keys
|
||||
dic.keys(); // => [1, 2, 123]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
That’s it. If you find it useful please give it a clap(s) or share with your friends ❤
|
||||
15
about.markdown
Normal file
15
about.markdown
Normal file
@@ -0,0 +1,15 @@
|
||||
---
|
||||
layout: page
|
||||
title: About
|
||||
permalink: /about/
|
||||
---
|
||||
|
||||
Welcome to by blog.
|
||||
I love writing about software engineering, leadership and anything in between.
|
||||
The blog is meant to be a practical guide for real-life situations.
|
||||
Currently I'm leading multiple teams in Amazon and in charge of all the SDKs we have in AWS. I enjoy enabling people to build amazing products.
|
||||
Before AWS, I worked at Facebook where I worked on FB stories and helped billion people to connect by sharing moments of their lives. Before Facebook, I started 3 companies across Israel.
|
||||
|
||||
In my free time, I love taking long walks while listening to audiobooks (follow me on GoodReads). I’m also into Jiu-Jitsu and I consider myself lucky if I don’t get hurt once a month.
|
||||
|
||||
Fun fact - I’m a private pilot so if you ever need a ride just let me know! You will need to provide the airplane though ;)
|
||||
6
index.markdown
Normal file
6
index.markdown
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
# Feel free to add content and custom Front Matter to this file.
|
||||
# To modify the layout, see https://jekyllrb.com/docs/themes/#overriding-theme-defaults
|
||||
|
||||
layout: home
|
||||
---
|
||||
Reference in New Issue
Block a user