mirror of
https://github.com/LukeHagar/sagivo-blog.git
synced 2025-12-06 04:21:15 +00:00
111 lines
7.2 KiB
Markdown
111 lines
7.2 KiB
Markdown
---
|
||
layout: post
|
||
title: The missing Dictionary in Solidity
|
||
description: (link to the github repo)
|
||
date: '2018-01-19T15:49:55.276Z'
|
||
categories: []
|
||
keywords: []
|
||
slug: /@sagivo/the-missing-dictionary-in-solidity-67b15e0c6d94
|
||
---
|
||
|
||
([link to the github repo](https://github.com/sagivo/solidity-utils))
|
||
|
||
If you ever wanted to interact with smart contracts and build on top of the block-chain before you probably heard of Solidity. That’s the programing language behind the Ethereum smart contracts. Being a new language comes with missing some typical data-structures you got used to in other languages. In this post I’ll describe the journey of creating the an `dictionary` data structure in Solidity.
|
||
|
||
### Define: <Dictionary>
|
||
|
||
Coming from languages like javascript, ruby, java, c# and others, `Dictionary` might represent different things usually known as `hash`/`map`/`hashmap`/`hashtable` etc… In this post I’ll define `Dictionary` as a generic data structure that allows you to do these basic operations:
|
||
|
||
`Set(key, value)` — store arbitrary value for a given key.
|
||
|
||
`Get(key) -> value` — retrieve a value for a specific key.
|
||
|
||
`Remove(key)`— remove a key.
|
||
|
||
`Keys() -> [id1, id2, ...id-n]` — get a list of all keys. (**The missing piece in Solidity**).
|
||
|
||
### The Current Problem
|
||
|
||
The easy part would be `Set` and `Get` as we can simply use the existed `[mapping](http://solidity.readthedocs.io/en/develop/types.html#mappings)` data type for it. Think of `mapping` as a hash table connecting a hashed key to a value. [Hash tables](https://en.wikipedia.org/wiki/Hash_table) will allow us to easily achieve O(1) efficiency for both `Get` and `Set`. The issue begins when we want to iterate over all the keys/values in the hash table.
|
||
|
||
In most of the modern languages we have a built-in `.keys()` function allows us to easily retrieve all the keys of a map. In solidity we don’t have it:
|
||
|
||
> Mappings are not iterable, but it is possible to implement a data structure on top of them. For an example, see [iterable mapping](https://github.com/ethereum/dapp-bin/blob/master/library/iterable_mapping.sol). \[[source](http://solidity.readthedocs.io/en/develop/types.html#mappings)\]
|
||
|
||
Ethereum offers a library that implement [iterable mapping](https://github.com/ethereum/dapp-bin/blob/master/library/iterable_mapping.sol). This solution combine an `array` together with `mapping` so each time you add an item to the hash table you also add another item to the extra array. This structure has some few problems:
|
||
|
||
**Data duplication** — the Ids stored in both mapping and array. As you know, storing information on the blockchain is expensive so you want to minimize the footprint as much as possible.
|
||
|
||
**Inefficient store **— when you delete an item from the map, the array simply set it’s index to 0. assuming you stored 1M items and deleted them all, you’ll have an array with 1M indexes assigned to initial value.
|
||
|
||
**Inefficient iteration & removal **— since the array that tracks ids is in sequential order, getting the next item means looping through items that might be deleted so if for instance the indexes in the array between `n` to `n+x` deleted means you’ll have `x` unneeded iteration operations that you wasted gas on just to get your next id.
|
||
|
||
### Can we do better?
|
||
|
||
The question I love to ask in each job interview is relevant here more than ever — can we do better? Smart contract requires gas to work. Since gas priced by code efficiency and storage requirements, we have to come up with better, leaner, faster data structure.
|
||
|
||
The main problem on the solution above is choosing array as a data structure to store and track ids of the mapping. Can we find a more efficient way to keep all the data in one place (to avoid duplication) yet enforce connection between ids so we can iterate and output all keys?
|
||
|
||
**First attempt**
|
||
|
||
One data structure that might be a good start is a [linked list](https://en.wikipedia.org/wiki/Linked_list). Linked list allows you easily track the next node so iteration will be very easy with no “gaps” between. Each node simply points on the next node.
|
||
|
||
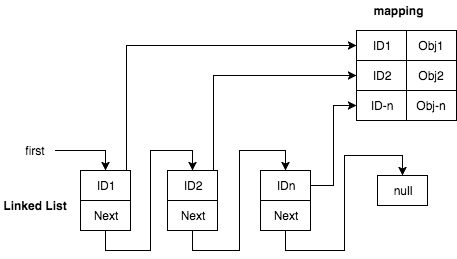
|
||
linked-list nodes combined with hash-table. each list node represent hash key
|
||
|
||
Pros —no mode “gaps” or array copy in case of removing a node. as we’re not using an array we can easily delete an item just by changing the `next` pointers.
|
||
|
||
Cons
|
||
|
||
1. Efficiency — to get the next item of a given key, or to delete a node we will need to iterate over the linked-list items yielding O(N) for `remove` operation.
|
||
2. Data duplication — keys exists both in the hash table and linked list.
|
||
|
||
**Final solution**
|
||
|
||
To avoid data duplication of keys and to get better retrieval time what if we can combine linked-list with hash map as one data-structure? This new data structure will be represented as a hash-map where each value is a linked-list node pointing on the next node and also containing the data.
|
||
|
||
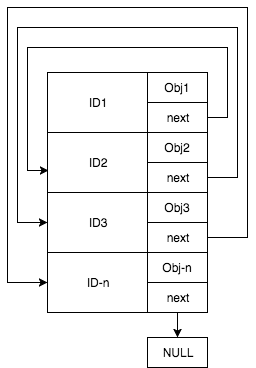
|
||
hash-table where each value is a linked-list node pointing on the next key
|
||
|
||
This data structure will combine the good of both linked-list and hash-table together.
|
||
|
||
Inserting or removing an item will require us to simply add/delete a key in the hash-table and adjust the node pointers — achieving O(1) performance (simple hash-map lookup).
|
||
|
||
Storing the nodes as part of the hash-map will also prevent a data-duplication among two different data structures as keys are saved only in one place (as keys of the mapping table) achieving less storage.
|
||
|
||
### Future improvements
|
||
|
||
1. Using [double linked list](https://en.wikipedia.org/wiki/Doubly_linked_list) to iterate over the array both ways.
|
||
2. Storing a `size` variable to easily get the number of items.
|
||
3. Using hash table as a data-structure to host the double-linked-list nodes will allow us to add more operations like `insertBefore`, `insertAfter`, `insertBeginning` and `insertEnd`.
|
||
4. Guarantee keys order based on inserting strategy (append beginning/end).
|
||
5. Extend the base node struct to allow different types as keys (like strings) and values.
|
||
|
||
### Use it in your smart contract today
|
||
|
||
I created a [repo of solidity utils](https://github.com/sagivo/solidity-utils) (includes all the suggested improvements) so everyone can easily use it in their projects. To import the new dictionary data structure all you need to do is:
|
||
|
||
```js
|
||
pragma solidity ^0.4.0;
|
||
// import the contract
|
||
import "github.com/sagivo/solidity-utils/contracts/lib/Dictionary.sol";
|
||
// have fun
|
||
contract Foo {
|
||
// declare and use new Dictionary structure
|
||
using Dictionary for Dictionary.Data;
|
||
Dictionary.Data private dic;
|
||
|
||
function Foo() public view returns (uint) {
|
||
dic.set(1, "value");
|
||
dic.set(2, "foo");
|
||
dic.set(123, "bar");
|
||
dic.set(1, "new value");
|
||
// get an item
|
||
dic.get(2); // => '0x666f6f' (byte hex of 'foo')
|
||
// get all keys
|
||
dic.keys(); // => [1, 2, 123]
|
||
}
|
||
}
|
||
```
|
||
|
||
That’s it. If you find it useful please give it a clap(s) or share with your friends ❤ |